Quartz定时任务默认都是并发执行,不仅仅是不同任务Job,还可以是同个Job的不同实例(JobDetail),意味着一次任务并不会等待上一次任务执行完毕,只要触发时间到达就会执行, 如果定时任执行太长,会长时间占用线程资源,导致其它任务堵塞。
Quartz定时任务默认也是无状态的,也就是每个Job实例都是独立的,每个Job实例的JobDataMap都是独有的,数据的改变互不影响。
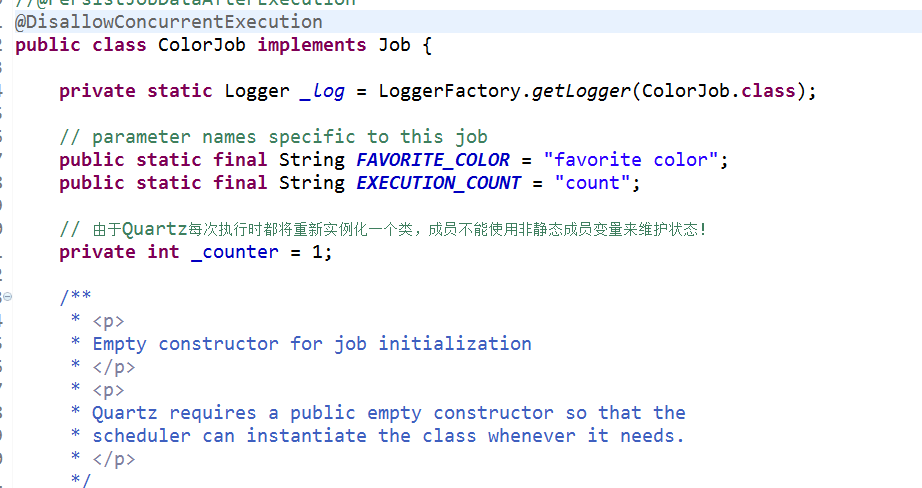
我们可以在自定义任务Job类加上类注解@DisallowConcurrentExecution来表示同个Job的不同实例(JobDetail)不允许并发(不同job还是可以并发),这样子,一次任务执行会等待上次任务执行完毕,才会继续执行,否则会阻塞。
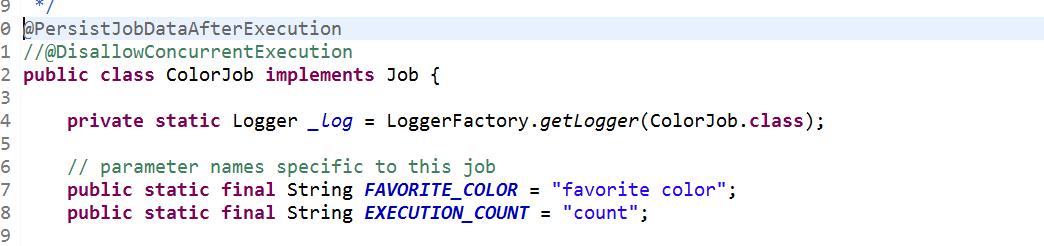
我们还可以在自定义任务Job类加上类注解@PersistJobDataAfterExecution让同个Job的不同实例(JobDetail)是有状态的,他们的数据是共享的,已存在的数据可能会被新的数据覆盖掉。值得注意的是,让任务变成有状态,最好是同时不允许并发,在并发情况下,数据读写是不确定的,可能造成不一致,是不可靠的。加上@PersistJobDataAfterExecution的同时,最好加上@PersistJobDataAfterExecution。
单Server
测试结果
这里的有状态和并发是指同一个Job的不同JobDetail实例。在默认情况下多个JobDetail实例之间是相互独立,互不影响的,即便是同个JobDetail实例的不同时间触发也是互不干扰。是支持并发的。而JobDetail中JobDataMap的数据初始化后也不会更新,是无状态的。
在任务Job类中加入注解@DisallowConcurrentExecution,则表示同一个JobDetail实例前后触发是相互影响的,下次触发要等待上次触发执行完毕,不同实例间则不需等待。
在任务Job类中加入注解@PersistJobDataAfterExecution,则表示同一个JobDetail实例前后触发JobDataMap是共享的,数据会发生更新。上次触发更新到JobDataMap的数据可以在下次触发时取到,为了防止并发竞争造成的不确定性,往往和@DisallowConcurrentExecution并发控制注解一起使用。
测试步骤
1、配置文件设置线程池大小为5,在线程充足的情形测试
org.quartz.threadPool.threadCount: 5
2、定义任务类ColorJob,把执行次数累加到JobDataMap里,休眠12s。
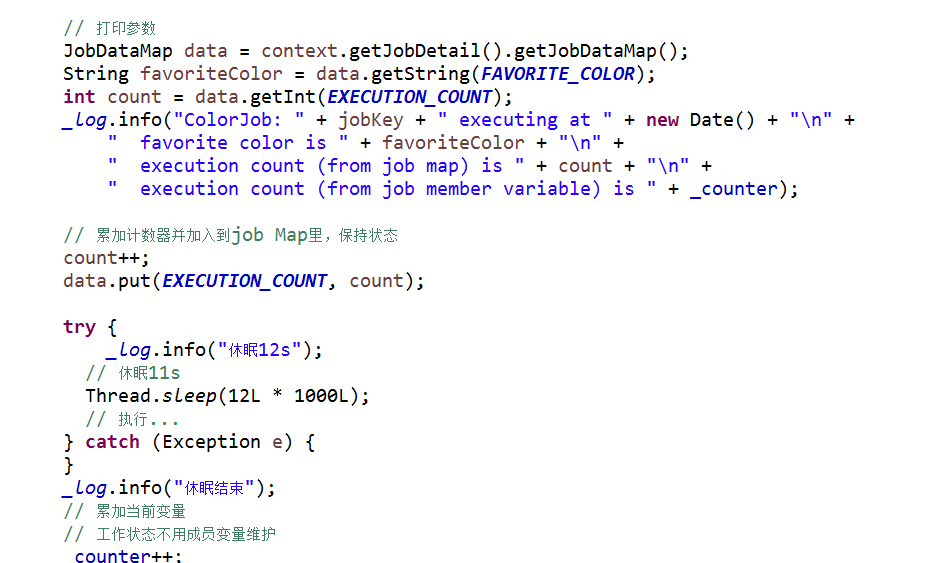
3、定义两个任务实例,每个任务实例都是10s后开始运行,每10s重复执行,重复4次,总运行5次

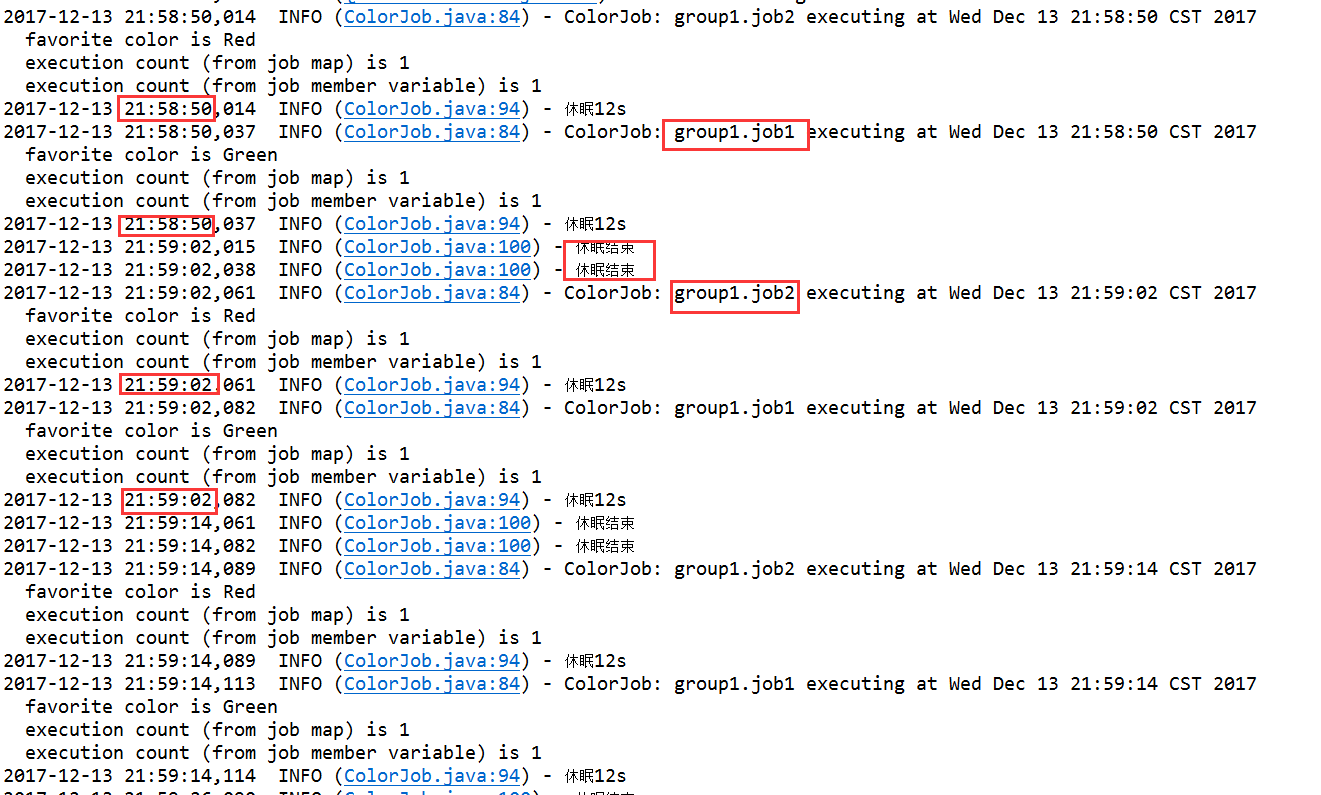
默认job是无状态,JobDataMap的数据不会发生更新,如测试场景结果,任务执行次数一直为1。支持并发,也在线程充足的情况下,同个任务实例触发也是相互独立,互不影响。如测试场景结果,job1每10s执行,但任务执行需要12s,下次触发时间到了就立即执行,不会等待。

4、在任务类ColorJob加入注解@DisallowConcurrentExecution,不会并发执行同一个job定义(ColorJob)的多个实例(JobDetail)。
重复执行第3步的测试用例,发现同一个ColorJob的两个实例是可以并发的,但同一时刻只允许一个相同实例执行。如测试场景结果,job1每10s执行,但任务执行需要休眠12s,下次触发时间到了要等待上次触发执行结束。这里比较诡异,没有休眠完12s就结束了。
5、在任务类ColorJob的注解换成@PersistJobDataAfterExecution,成功执行了job类的execute方法后(没有发生任何异常),更新JobDetail中JobDataMap的数据下次触发时,JobDataMap中是更新后的数据,Job的状态就体现在持续的JobDataMap数据。
重复执行第3步的测试用例,发现打印的执行次数发生变化,即JobDetail实例的JobDataMap数据更新了。但在并发情形下,JobDataMap数据发生了不确定。
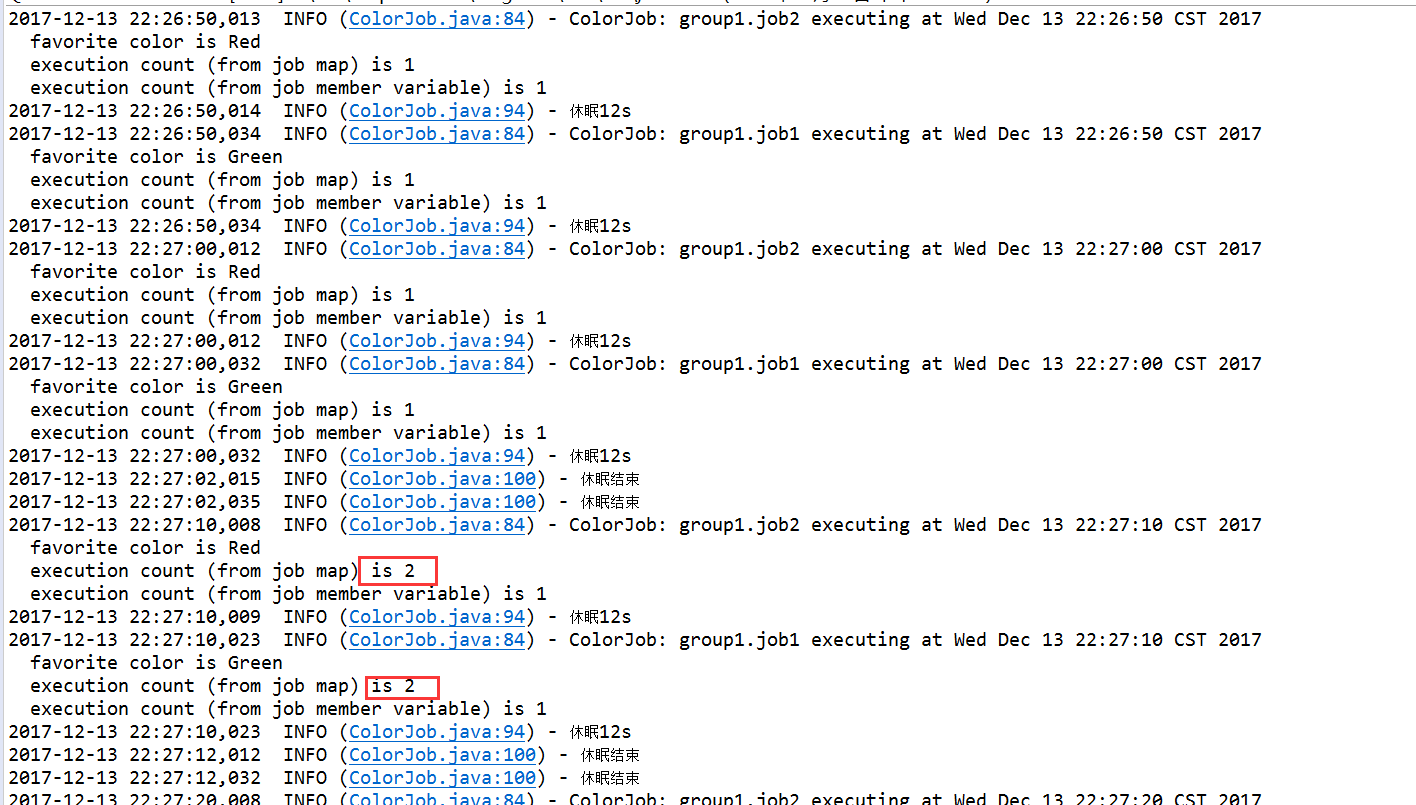
6、在任务类ColorJob加入注解@PersistJobDataAfterExecution和
@DisallowConcurrentExecution,如果需要JobDataMap状态更新,就应该变成同步,防止并发导致的竞争,造成数据脏乱。重复执行第3步的测试用例,发现打印的执行次数发生变化,禁止并发后,与测试场景,每10s重复执行,执行5次,发生吻合。
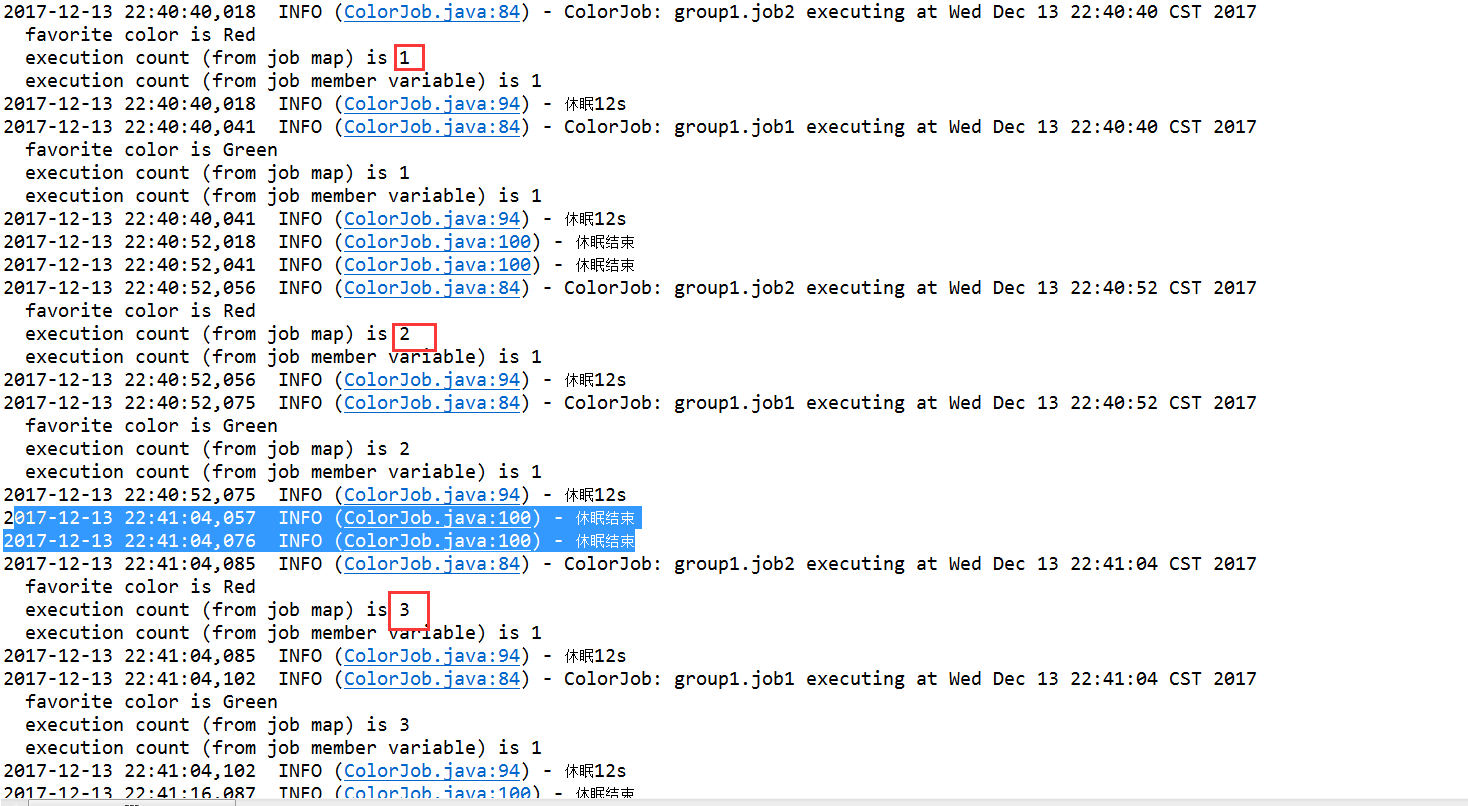
集群
测试结果
集群下任务实例间的并发控制与【单server】一致,但故障情况下,故障期间未完成任务丢失,状态更新可能会发生不确定,可设置为可恢复的任务,集群可以重跑某一节点故障期间丢失的任务。
测试步骤
1、与【单server】步骤6的测试用例,启用两个环境,构造集群测试。相继启动两个环境,发现会自动负载均衡任务实例。
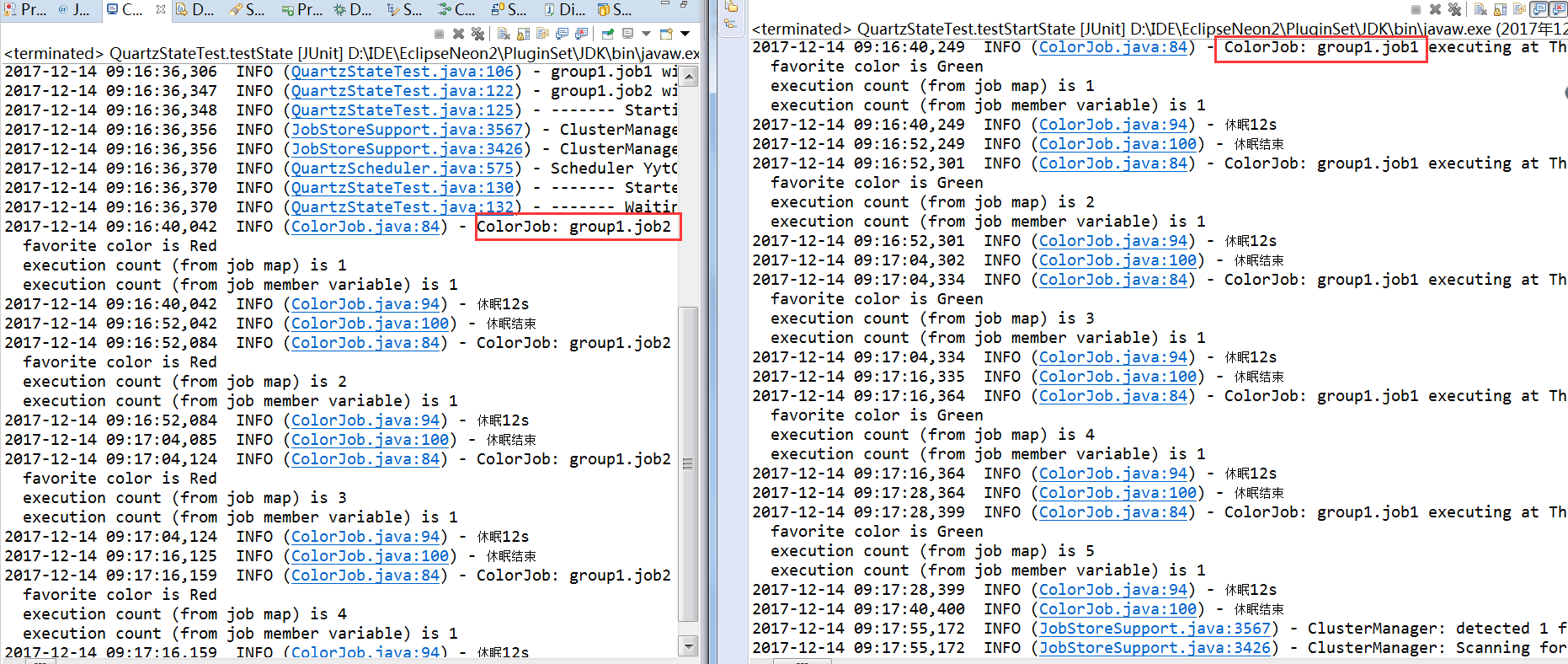
2、手动关闭其中一个应用(job2此时执行第四次还未结束),集群节点会检测到其他节点的健康状况,如果某节点丢失了,则接管其节点的Job任务,等待下次触发,故障时间的任务却丢失了。而检测频率由配置org.quartz.jobStore.clusterCheckinInterval参数决定,默认15000ms。但JobDataMap的数据更新状态由于故障发生了不确定性(因为要任务执行结束才更新状态)。如下图,job2的最终状态保持在4,与实际的执行次数5不一致。
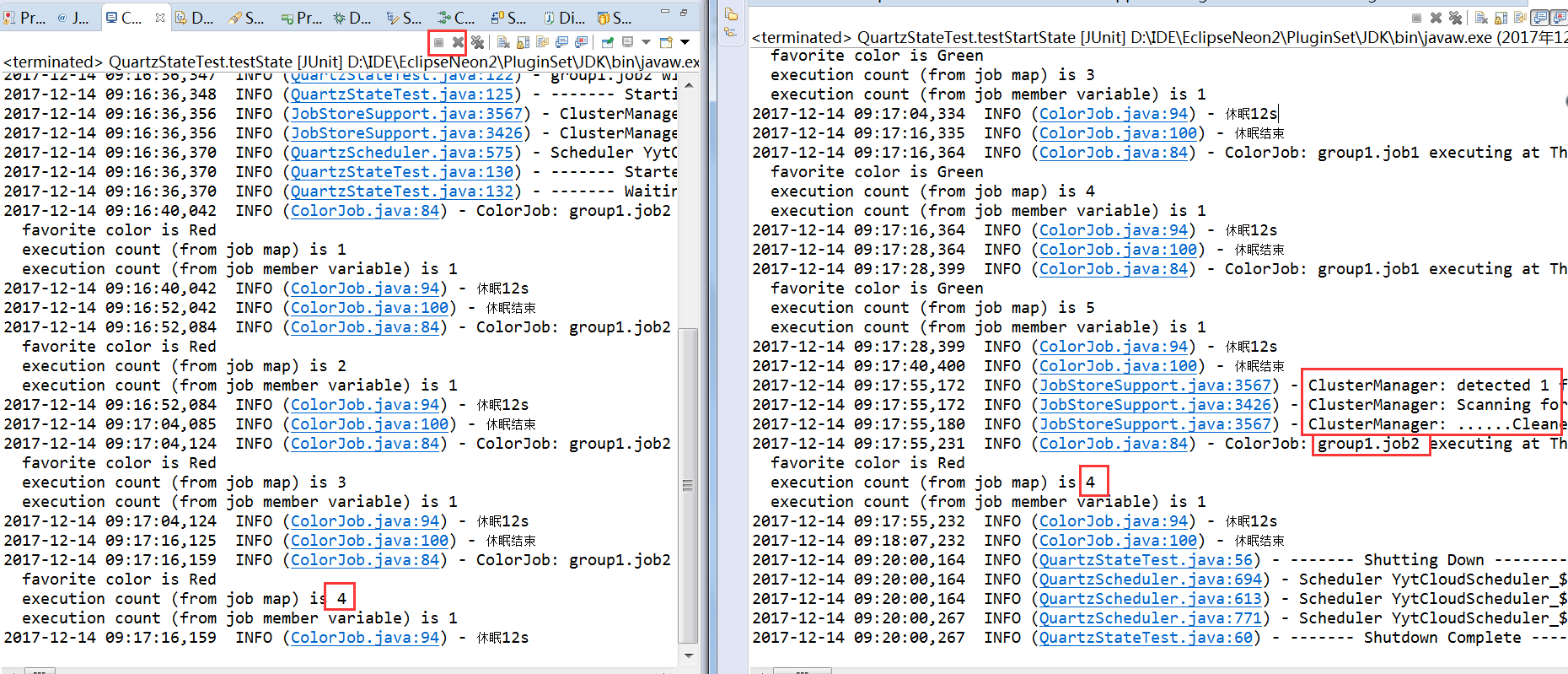
3、将job2设为可恢复的任务

重跑集群测试,关闭其中一个应用(job2此时执行第四次还未结束),但另外一个调度会接管恢复异常故障时间丢失的任务,重新执行。

跨集群
测试结果
不同集群的任务实例相互之间没有任何关联。
测试步骤
1、运行两个测试用例,启用不同的配置。用例采用【单server】步骤6的测试用例
其中,设置不同调度实例
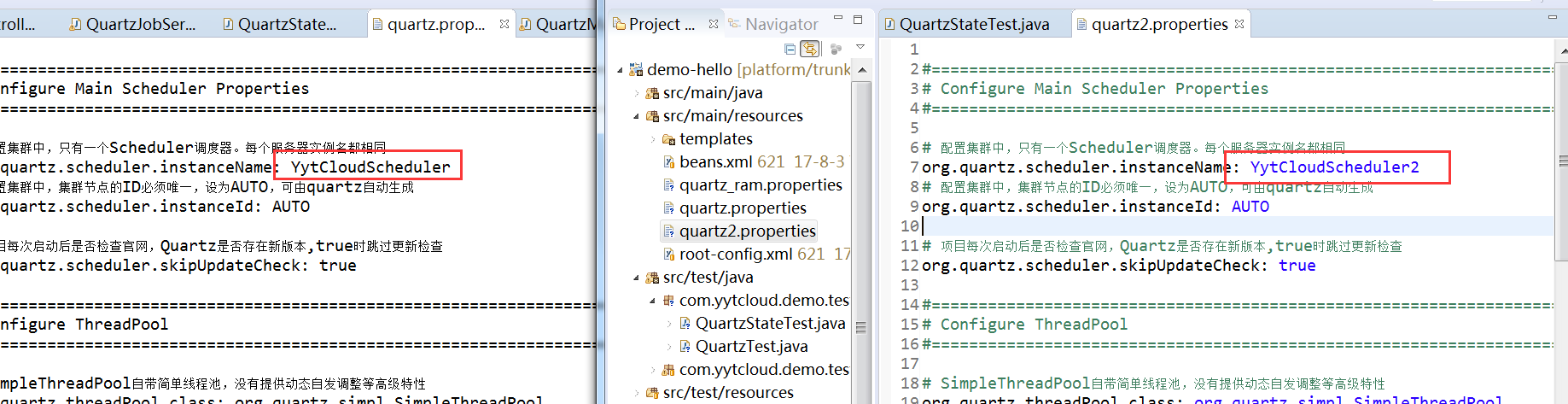
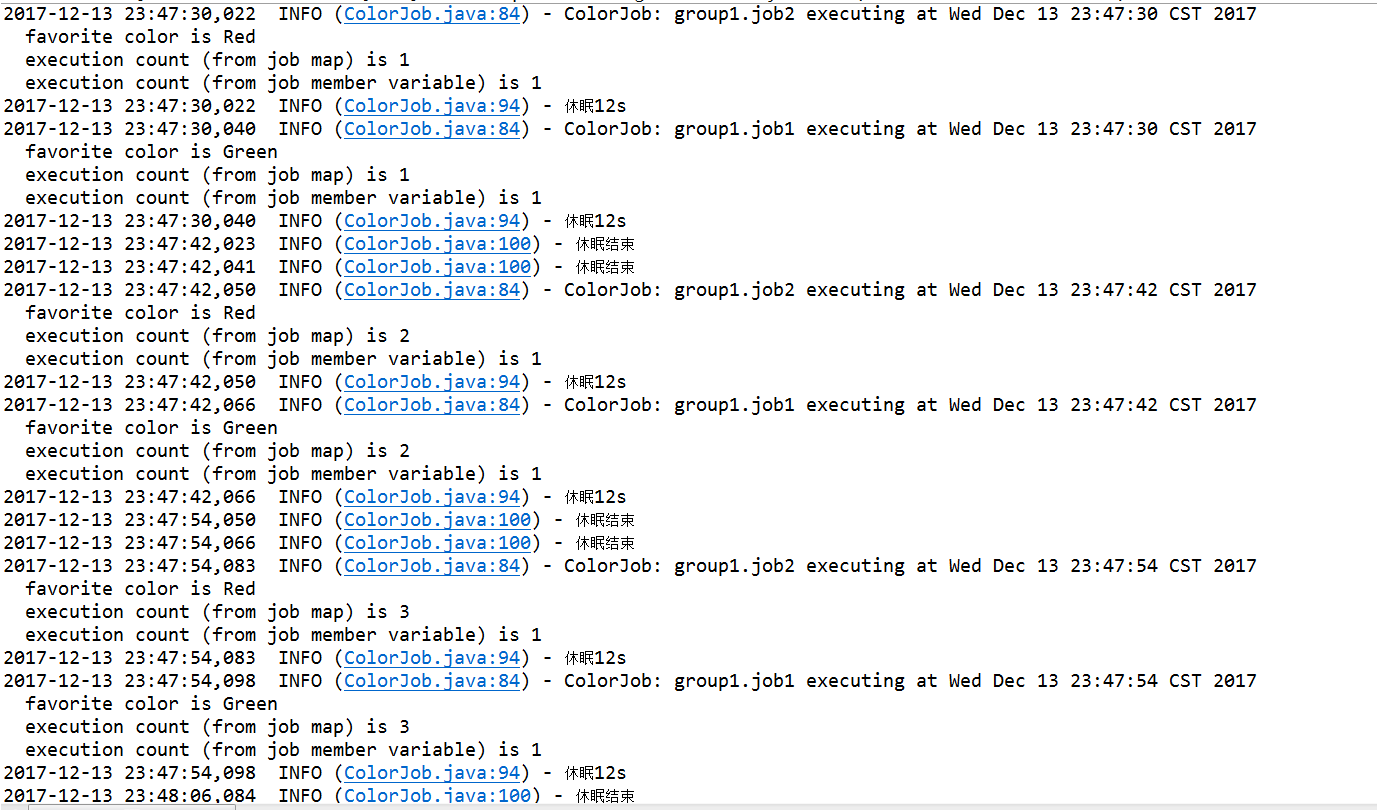
用两个环境分别测试,发现两个实例互不影响。与【单server】步骤6测试结果一致。
代码参见
job_detail任务表结构定义可以看出有状态位标示是否可并发,是否有状态,是否可恢复等等,也就意味着任务的并发控制和是否有状态也会持久化,任务动态操纵也伴随着这些标志位的改变。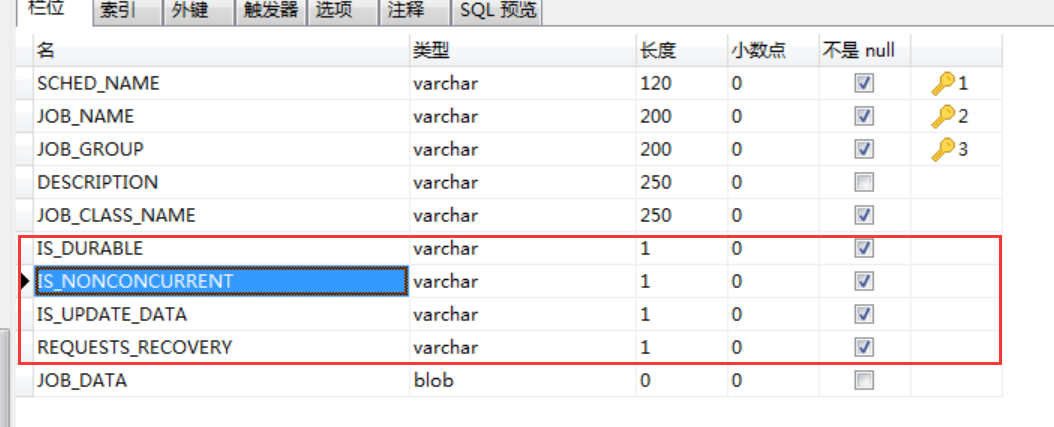
对于同个Job不允许同时并发的不同JobDetail实例,它会过滤掉其他JobDetail的触发器
org.quartz.impl.jdbcjobstore.JobStoreSupport.acquireNextTrigger(Connection, long, int, long)
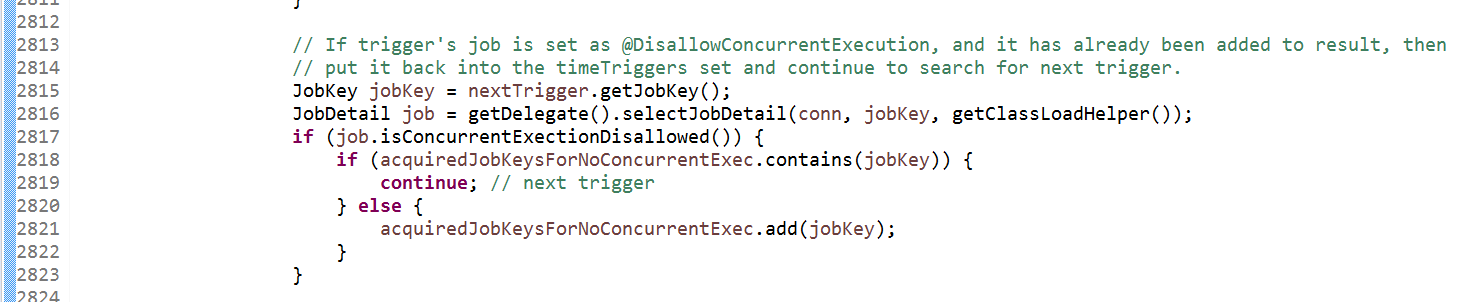
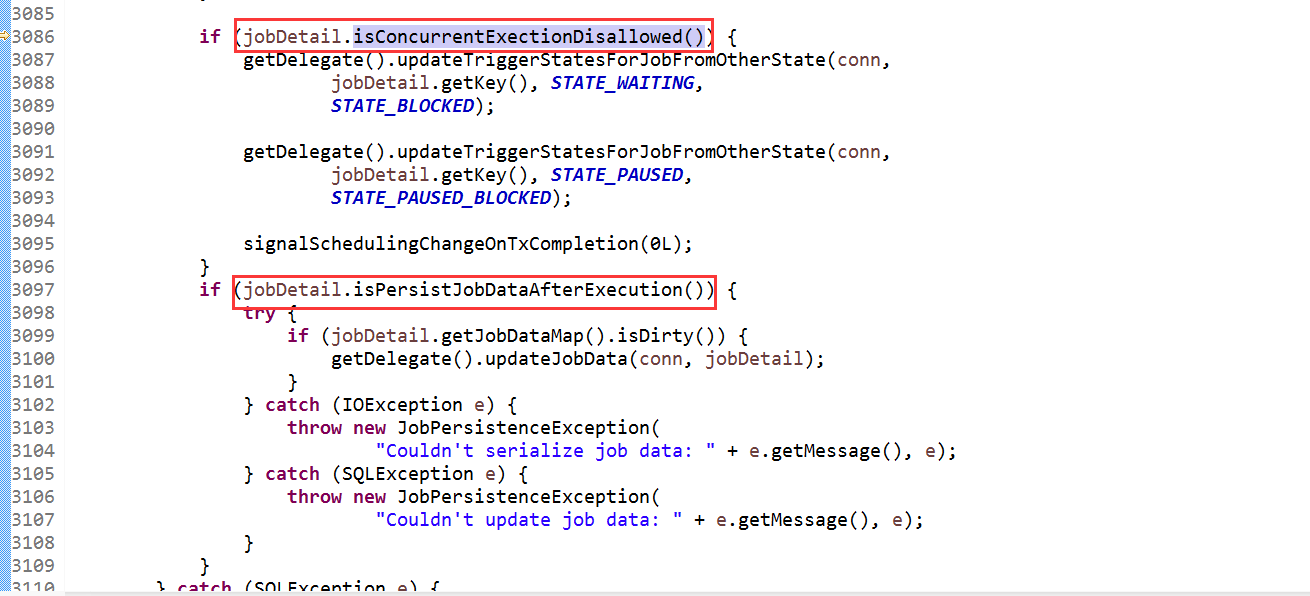
任务触发完成后,根据会根据是否运行并发和是否有状态,进行触发器状态和Job数据更新
org.quartz.impl.jdbcjobstore.JobStoreSupport.triggeredJobComplete(Connection, OperableTrigger, JobDetail, CompletedExecutionInstruction)
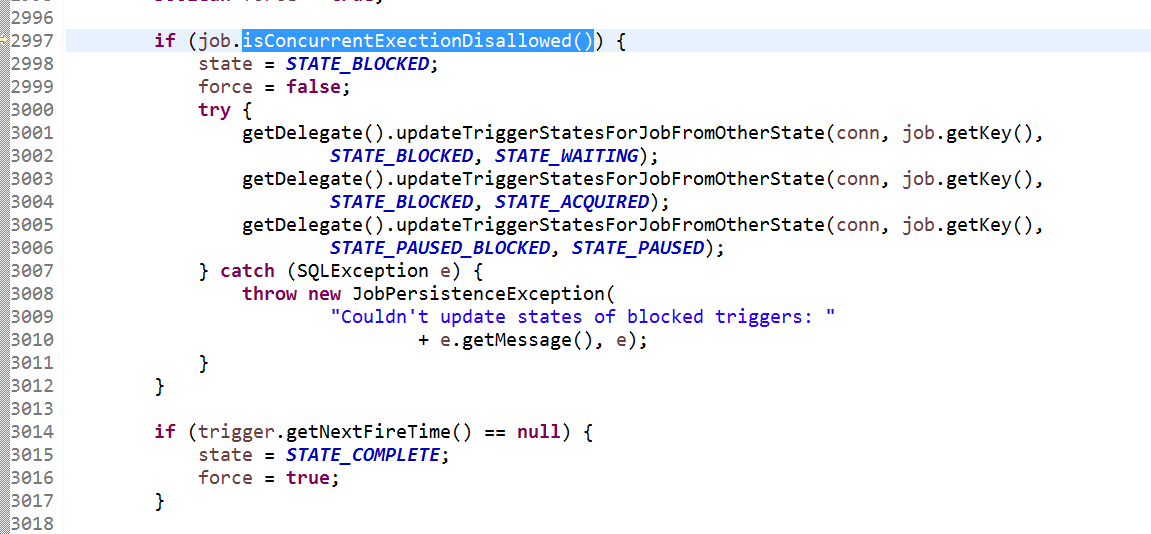
org.quartz.impl.jdbcjobstore.JobStoreSupport.triggerFired(Connection, OperableTrigger)
总结
quartz定时任务默认是并发和无状态的,可通过使用类注解@DisallowConcurrentExecution和@PersistJobDataAfterExecution让同个Job的不同JobDetail实例可以进行控制并发执行和数据共享有状态,这种结果,在集群情况下也同样试用,只是默认故障期间未完成任务状态会丢失,可以设置为可恢复(requestRecovery),任务应用重启,可故障恢复。


发表评论