分词按照官方的说法就是将连续的字序列按照一定的规范重新组合成词序列的过程。先上一道测试例子:
工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作
一不小心就重口味了。。。
一元分词
我们可以看下,Solr 默认的一元标准分词【managed-schema】配置文件里面定义fieldType:
- <fieldType name=“text_general” class=“solr.TextField” positionIncrementGap=“100” multiValued=“true”>
- <analyzer type=“index”>
- <tokenizer class=“solr.StandardTokenizerFactory”/>
- <filter class=“solr.StopFilterFactory” ignoreCase=“true” words=“stopwords.txt” />
- <!– in this example, we will only use synonyms at query time
- <filter class=“solr.SynonymFilterFactory” synonyms=“index_synonyms.txt” ignoreCase=“true” expand=“false”/>
- —>
- <filter class=“solr.LowerCaseFilterFactory”/>
- </analyzer>
- <analyzer type=“query”>
- <tokenizer class=“solr.StandardTokenizerFactory”/>
- <filter class=“solr.StopFilterFactory” ignoreCase=“true” words=“stopwords.txt” />
- <filter class=“solr.SynonymFilterFactory” synonyms=“synonyms.txt” ignoreCase=“true” expand=“true”/>
- <filter class=“solr.LowerCaseFilterFactory”/>
- </analyzer>
- </fieldType>
按原子粒度直接切割了,分成单字,这可能也是最保险的方式了。

smart中文分词
Solr 自带的smart中文分词是中科院计算所ICTCLAS分词系统简化后的版本;没有词性标注;没有人名、地名识别;没有采用隐马模型进行分词,而是采用的动态规划计算最短路径。贴下配置:
- <!– smartcn –>
- <fieldType name=“textSmartcn” class=“solr.TextField”>
- <analyzer class=“org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer”/>
- </fieldType>
将【solr-6.2.1\contrib\analysis-extras\lucene-libs】下的lucene-analyzers-smartcn-6.2.1.jar复制到【solr-6.2.1\contrib\extraction\lib】扩展目录下,查看下分词效果:
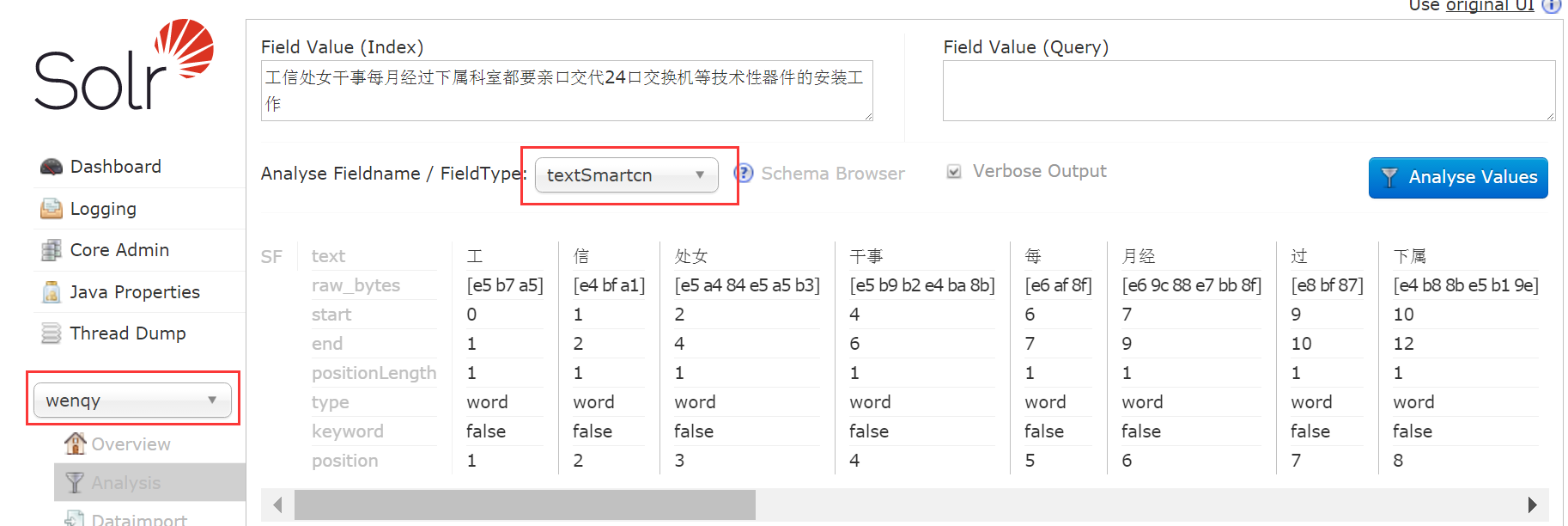
工 | 信 | 处女 | 干事 这个分错了。。。。
mmseg4j
mmseg4j 用 Chih-Hao Tsai 的 MMSeg 算法(可以去:http://technology.chtsai.org/mmseg/)实现的中文分词器,并实现 Lucene 的 analyzer 和 solr 的TokenizerFactory 以方便在Lucene和Solr中使用。MMSeg 算法有几种分词方法:Simple、Complex和MaxWord,都是基于正向最大匹配。Complex 加了四个规则过虑。官方说:词语的正确识别率达到了 98.41%。mmseg4j 已经实现了这些分词算法。
先送上配置:
- <!– mmseg4j –>
- <fieldtype name=“textComplex” class=“solr.TextField” positionIncrementGap=“100”>
- <analyzer>
- <tokenizer class=“com.chenlb.mmseg4j.solr.MMSegTokenizerFactory” mode=“complex” dicPath=“dic”/>
- </analyzer>
- </fieldtype>
- <fieldtype name=“textMaxWord” class=“solr.TextField” positionIncrementGap=“100”>
- <analyzer>
- <tokenizer class=“com.chenlb.mmseg4j.solr.MMSegTokenizerFactory” mode=“max-word” />
- </analyzer>
- </fieldtype>
- <fieldtype name=“textSimple” class=“solr.TextField” positionIncrementGap=“100”>
- <analyzer>
- <tokenizer class=“com.chenlb.mmseg4j.solr.MMSegTokenizerFactory” mode=“simple” dicPath=“D:/solr/solr-6.2.1/example/” />
- </analyzer>
- </fieldtype>
看下效果:
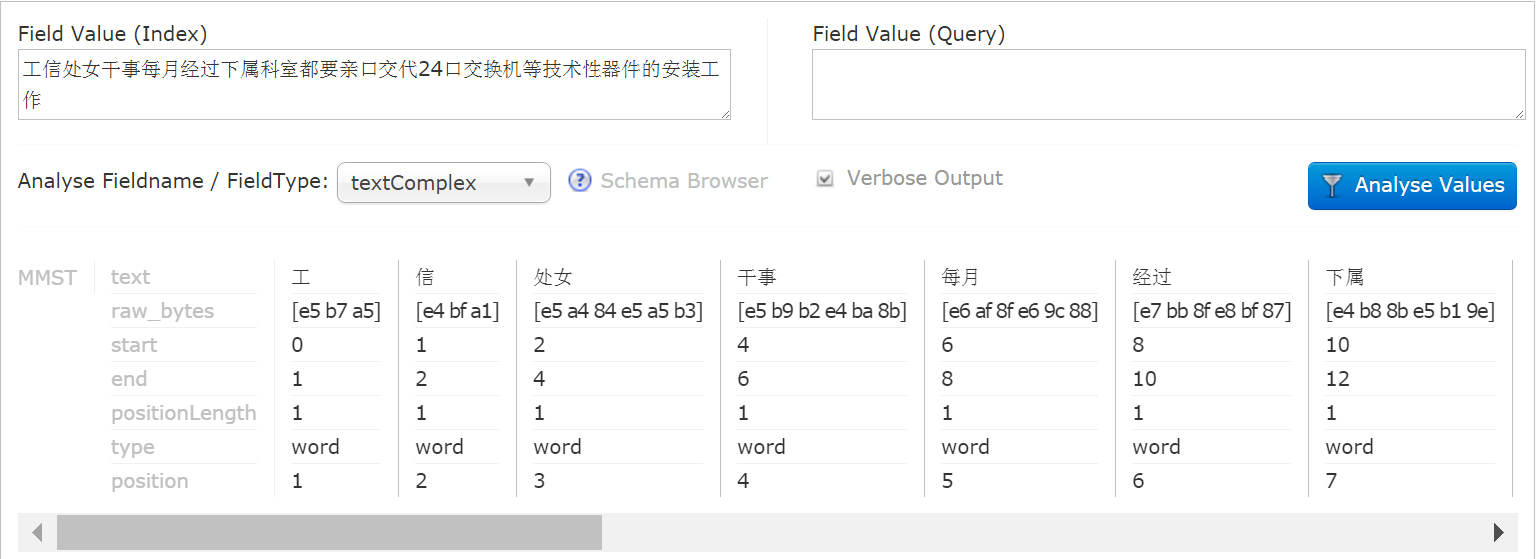
工 | 信 | 处女 | 干事 这个分错了。。。。这是基于词典的,我把【工信处】这个词直接加到核心词典里了:

再重新看下分词效果:
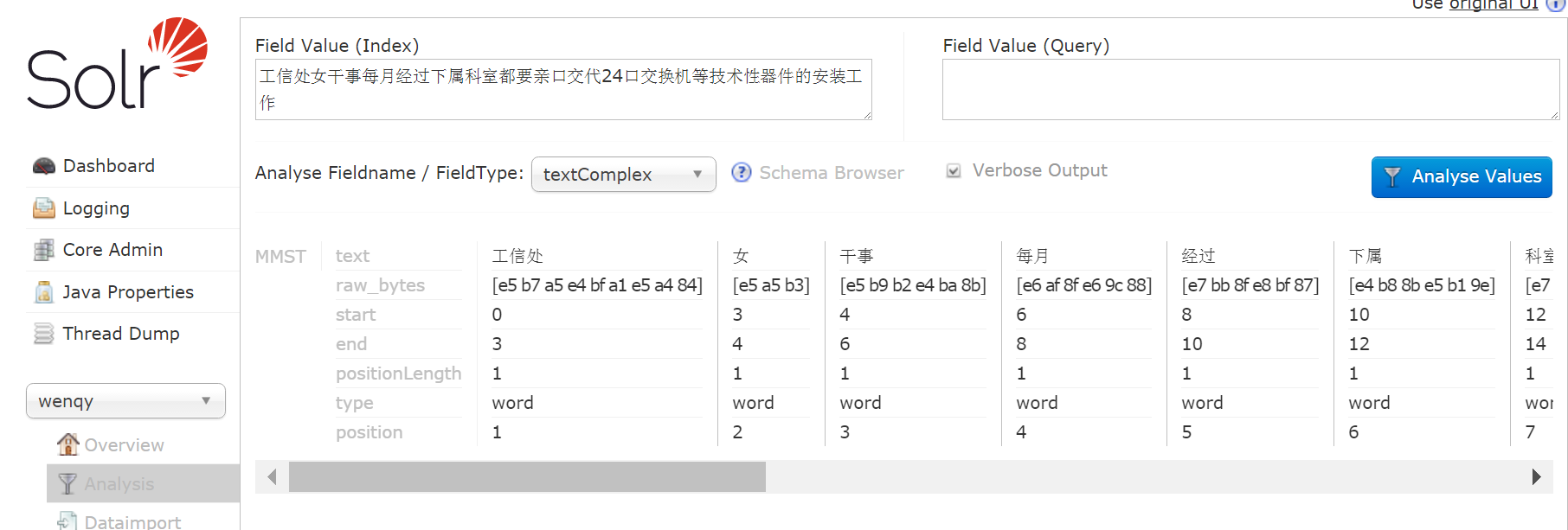
直接分成了 工信处 | 女 | 干事 效果好多了。。。当然是可以自定义词典的,可以看下这些词典:
chars.dic,是单个字,和对应的频率,一行一对,字在全面,频率在后面,中间用空格分开。这个文件的信息是 complex 模式要用到的。在最后一条过虑规则中使用了频率信息。
units.dic,是单位的字,如:分、秒、年,也是一行一条。主要是在数字后面的单位信息切分好,不与words.dic中的词有混淆。
words.dic,是核心的词库文件,一行一条,不需要其它任何数据(如词长)。原先使用 rmmseg(ruby 的 mmseg 实现) 的词库。之后 mmseg4j 改用 sogou 词库,可以到搜狗实验室http://www.sogou.com/labs/ 的数据资源下载。
贴下引用的jar包:

Paoding庖丁解牛
贴上paoding配置:
- <!– Paoding –>
- <fieldType name=“textPaoding” class=“solr.TextField”>
- <analyzer class=“net.paoding.analysis.analyzer.PaodingAnalyzer” />
- </fieldType>
查看下分词效果图:

工信 | 处女 | 干事 效果也差了。。。这也是可以自定义词典的,改下分词模式和自定义词典。这个没有尝试。。。将【paoding-analysis-2.0.4.jar】放到【solr-6.2.1\server\solr-webapp\webapp\WEB-INF\lib】路径下。
IK-Analyzer
IK Analyzer是一个开源的,基于Java 语言开发的轻量级的中文分词工具包。采用了特有的“正向迭代最细粒度切分算法“,支持细粒度和智能分词两种切分模式。可以使用maven进行依赖管理:
- <dependency>
- <groupId>org.wltea.ik-analyzer</groupId>
- <artifactId>ik-analyzer</artifactId>
- <version>3.2.8</version>
- </dependency>
要安装到本地Maven repository,使用如下命令,将自动编译,打包并安装:
mvn install -Dmaven.test.skip=true
贴上配置:
- <!– ik-Analyzer –>
- <fieldType name=“textIk” class=“solr.TextField”>
- <analyzer class=“org.wltea.analyzer.lucene.IKAnalyzer”/>
- </fieldType>
查看效果:
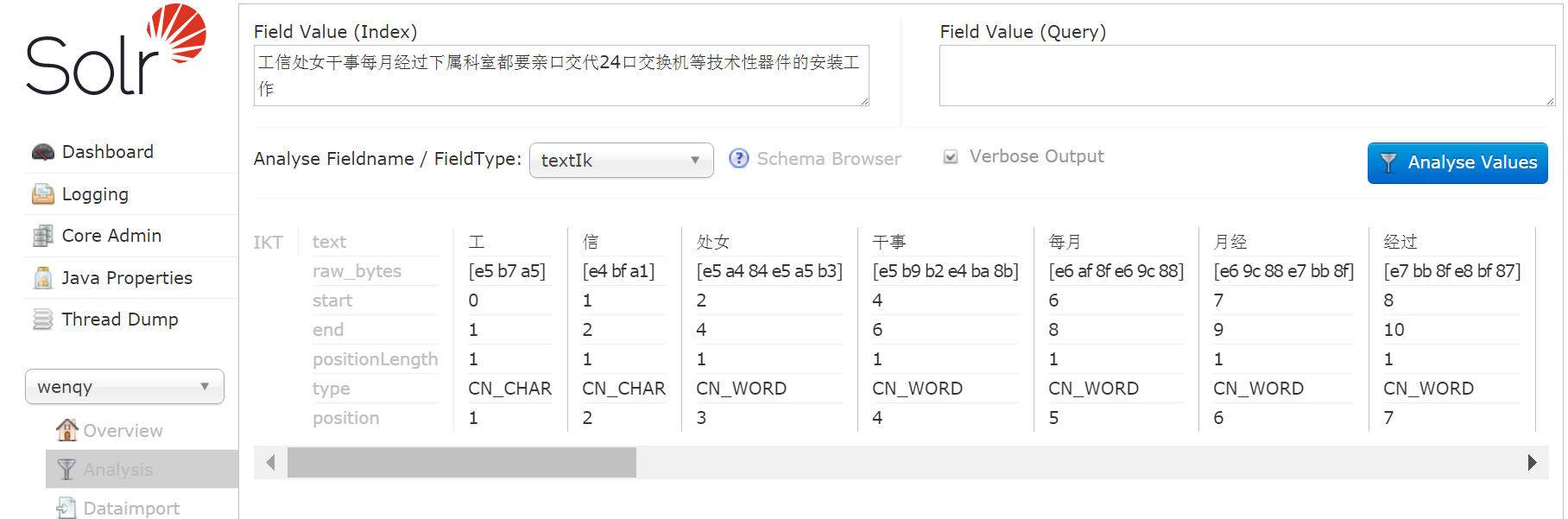
工 | 信 | 处女 | 干事 分词效果。。。。将【IK-Analyzer-ForSolr6.2.1.jar】放到【solr-6.2.1\server\solr-webapp\webapp\WEB-INF\lib】路径下。Ik默认实现最细粒度切分算法。在自定义扩展词典中Ext.dic里加了词:工信处,分词效果:
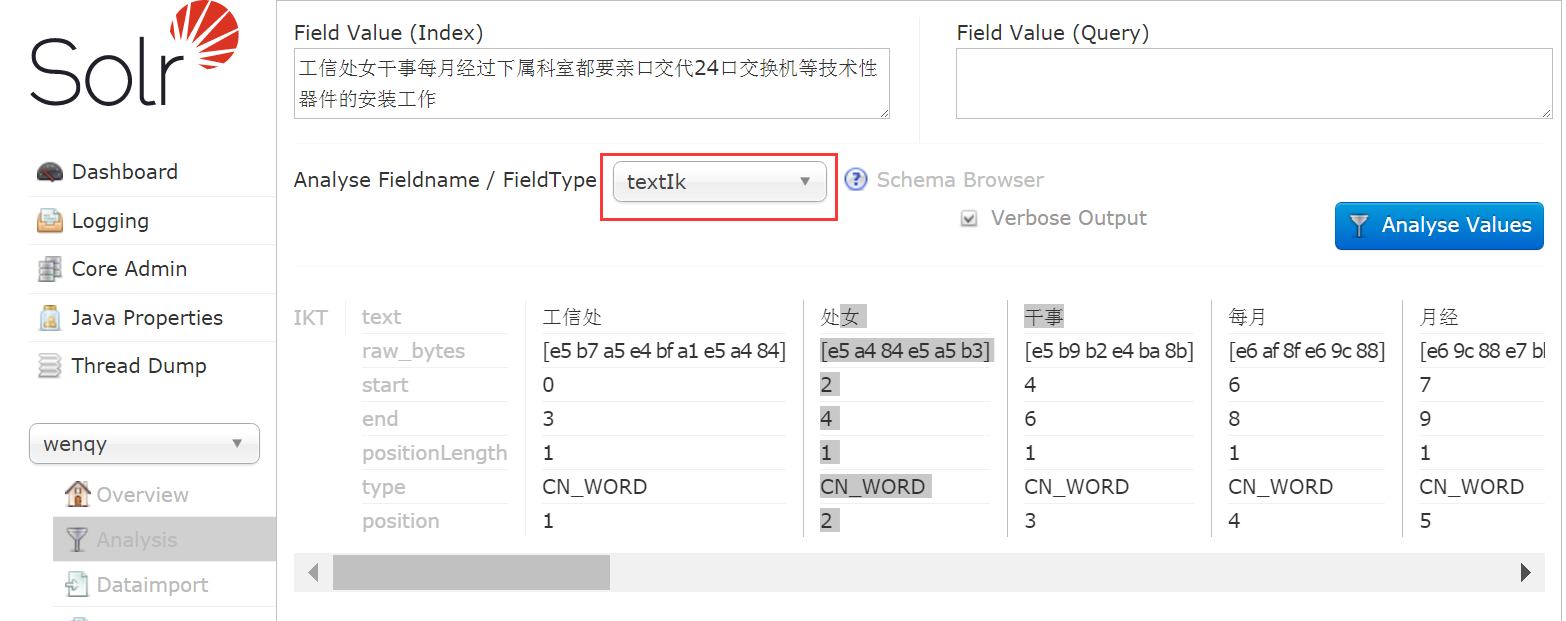
变成了 工信处 | 处女 | 干事 。。。。。再加个:女干事,效果:
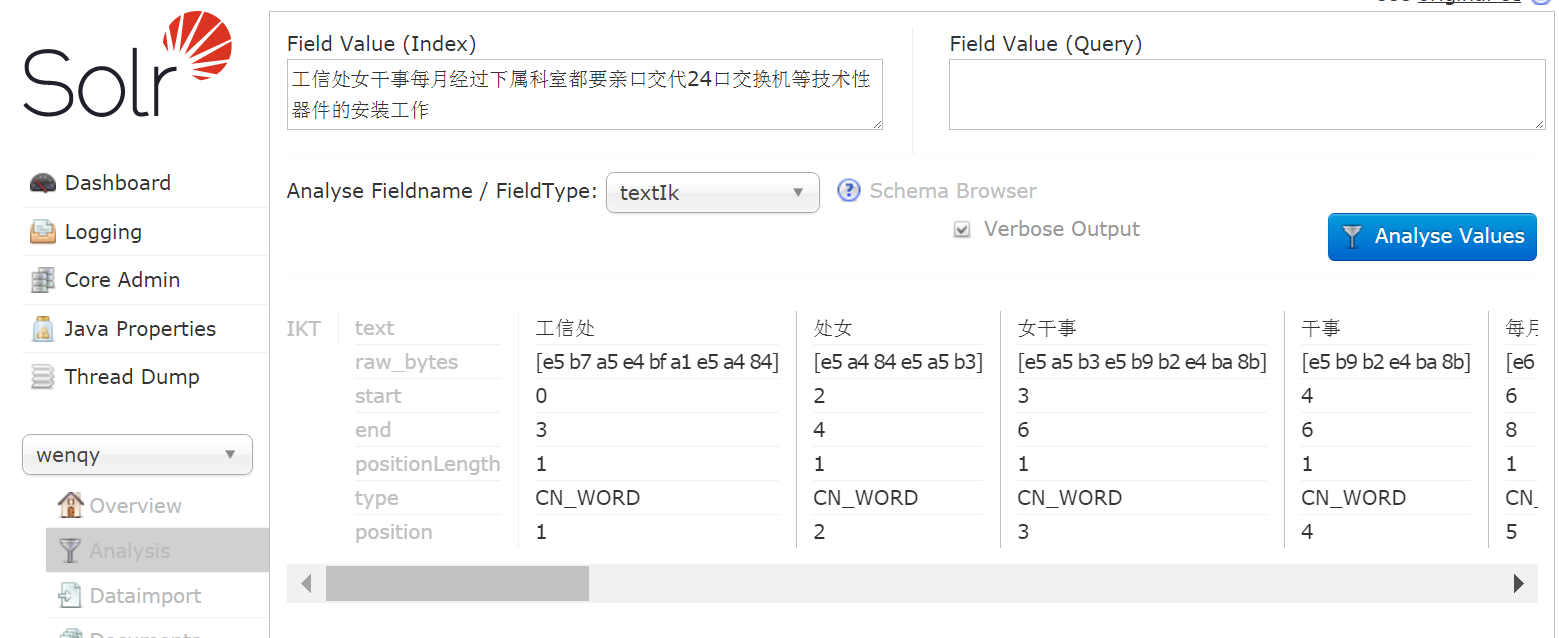
直接变成了 工信处 | 处女 | 女干事 | 干事 。。。这个是最细粒度切分,看下IKAnalyzer类源码,默认的就是最细粒度切分,要启用智能模式了,改源码,重新打包:【IKAnalyzer_AI-6.2.1.jar】

前面堵住了,后面又漏了 口交 | 换机 ,查了下核心词典,发现【口交】和【交换机】两个词都是有的,而【交换机】在后面,交换下两词的顺序,效果一样,无解。。。
Ansj
一个基于n-Gram+CRF+HMM的中文分词的java实现。实现了中文分词. 中文姓名识别 . 用户自定义词典,关键字提取,自动摘要,关键字标记等功能。贴上配置:
- <!– Ansj –>
- <fieldType name=“textAnsj” class=“solr.TextField”>
- <analyzer class=“org.ansj.lucene6.AnsjAnalyzer” />
- </fieldType>
分词效果:
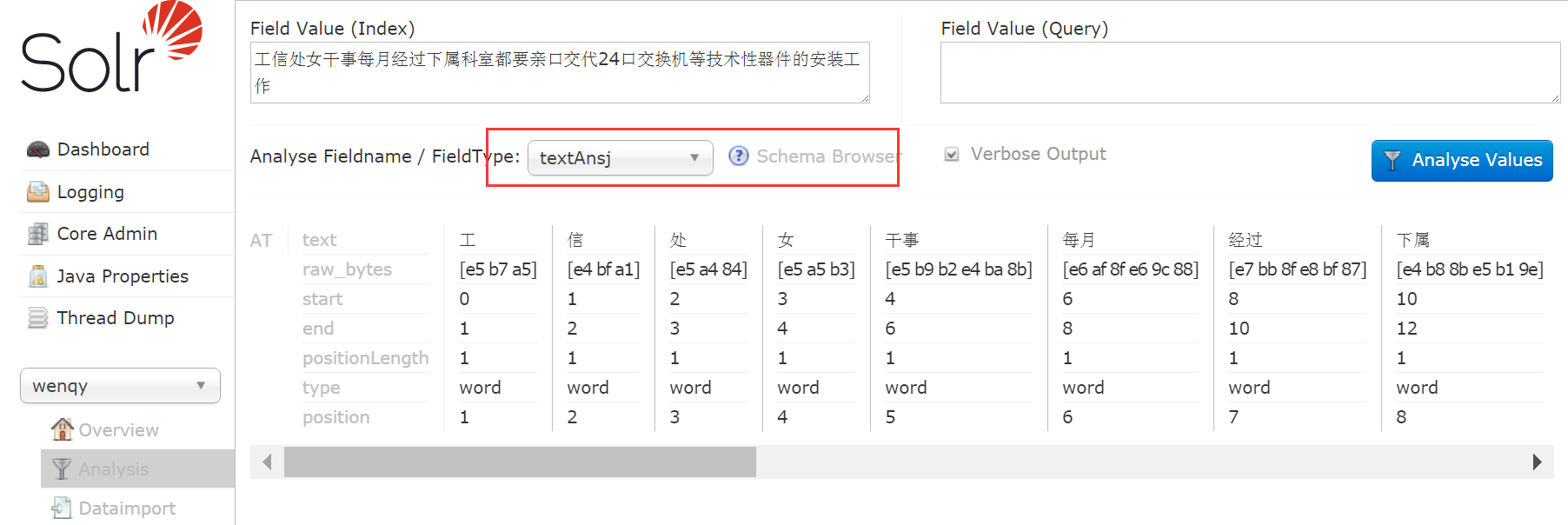
工 | 信 | 处 | 女 | 干事 还好。。。将【ansj_seg-5.0.1-all-in-one.jar】、【ansjLuceneForSolr6.jar】和【tree_split-1.4.jar】放到【solr-6.2.1\server\solr-webapp\webapp\WEB-INF\lib】路径下。
试用了这些中文分词,感觉都大同小异吧,准确率都那样。基于词典的都有滞后性,无法发现新词。很感谢这些开源者,不过,好多分词,官方都停止更新了,还要自己找第三方,或者修改源码等等。需要尝试,也不是那么容易的。还有很多分词,比如:word分词,结巴分词,盘古分词,不一一列举了,尝试先到此为止吧。
附录参考
https://github.com/koth/kcws
https://github.com/chenlb/mmseg4j-solr
https://github.com/chulung/IK-Analyzer-6
https://github.com/lgnlgn/ansj4solr
https://github.com/NLPchina/ansj_seg/wiki/%E8%8E%B7%E5%BE%97jar%E5%8C%85
https://github.com/ysc/cws_evaluation 中文分词器分词效果评估对比
https://github.com/ysc/word
http://ictclas.nlpir.org/ NLPIR自然语言处理


发表评论