Quartz是原生支持应用集群下的任务调度,查下摘自官网的架构图:
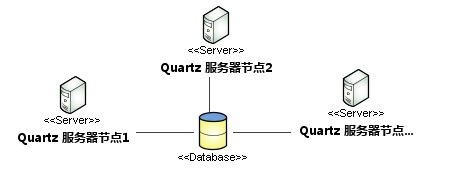
Quartz集群中的每个节点是一个独立的Quartz任务应用,它又管理着其他的节点。该集群需要分别对每个节点分别启动或停止,不像一些应用服务器的集群需要彼此通信,独立的Quartz节点并不与另一个节点或是管理节点通信。Quartz应用是通过共用相同数据库表来感知到另一应用。也就是说只有使用持久化JobStore存储Job和Trigger才能完成Quartz集群。
数据库核心表
在Quartz源码的docs/dbTables目录下,存放了针对不同数据库Quartz所需要的数据库表。以Mysql为例,看下需要的表:
| 表名 | 描述 |
| QRTZ_CALENDARS | 存储Quartz的Calendar信息 |
| QRTZ_CRON_TRIGGERS | 存储CronTrigger,包括Cron表达式和时区信息 |
| QRTZ_FIRED_TRIGGERS | 存储与已触发的Trigger相关的状态信息,以及相联Job的执行信息 |
| QRTZ_PAUSED_TRIGGER_GRPS | 存储已暂停的Trigger组的信息 |
| QRTZ_SCHEDULER_STATE | 存储少量的有关Scheduler的状态信息,和别的Scheduler实例 |
| QRTZ_LOCKS | 存储程序的悲观锁的信息 |
| QRTZ_JOB_DETAILS | 存储每一个已配置的Job的详细信息 |
| QRTZ_JOB_LISTENERS | 存储有关已配置的JobListener的信息 |
| QRTZ_SIMPLE_TRIGGERS | 存储SimpleTrigger,包括重复次数、间隔、以及已触的次数 |
| QRTZ_BLOG_TRIGGERS | Trigger作为Blob类型存储 |
| QRTZ_TRIGGER_LISTENERS | 存储已配置的TriggerListener的信息 |
| QRTZ_TRIGGERS | 存储已配置的Trigger的信息 |
Quartz的集群部署方案在架构上是分布式的,没有负责集中管理的节点,而是利用数据库行锁的方式来实现集群环境下进行并发控制。
一个调度器实例在集群模式下首先要获取 {0}LOCKS 表中对应的行级锁,
向MySQL获取行锁语句为
select * from {0}LOCKS where sched_name = ? and lock_name = ? for update
{0}会替换为配置文件默认配置的QRTZ_。sched_name为应用集群的实例名,lock_name就是行级锁名。Quartz主要由两个行级锁。
| lock_name | desc |
| STATE_ACCESS | 状态访问锁 |
| TRIGGER_ACCESS | 触发器访问锁 |
Quartz集群争用触发器行锁,锁被占用只能等待。获取触发器行锁后,先获取需要待触发的其他触发器信息。数据库更新触发器状态信息,及时释放触发器行锁,供其他调度实例获取,然后在进行触发器任务调度操作。对数据库操作就要先获取行锁。
集群配置
定义quartz.properties配置文件默认放在应用classpath路径下,其他路径只能自己手动加载properties。下面是集群配置参考
#集群中应用采用相同的Scheduler实例 org.quartz.scheduler.instanceName: wenqyScheduler #集群节点的ID必须唯一,可由quartz自动生成 org.quartz.scheduler.instanceId: AUTO #通知Scheduler实例要它参与到一个集群当中 org.quartz.jobStore.isClustered: true #需持久化存储 org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate #数据源 org.quartz.jobStore.dataSource=myDS #quartz表前缀 org.quartz.jobStore.tablePrefix=QRTZ_ #数据源配置 org.quartz.dataSource.myDS.driver: com.mysql.jdbc.Driver org.quartz.dataSource.myDS.URL: jdbc:mysql://localhost:3306/ncdb org.quartz.dataSource.myDS.user: root org.quartz.dataSource.myDS.password: 123456 org.quartz.dataSource.myDS.maxConnections: 5 org.quartz.dataSource.myDS.validationQuery: select 0
同一集群下,instanceName必须相同,instanceId可自动生成,isClustered为true,持久化存储,指定数据库类型对应的驱动类和数据源连接。
集群测试
测试结果:Quartz集群管理可以避免应用在集群环境下重复执行相同的Job。
测试步骤:
在两个IDE环境下测试同一份demo应用,运行相同的任务。应用采用集群配置。
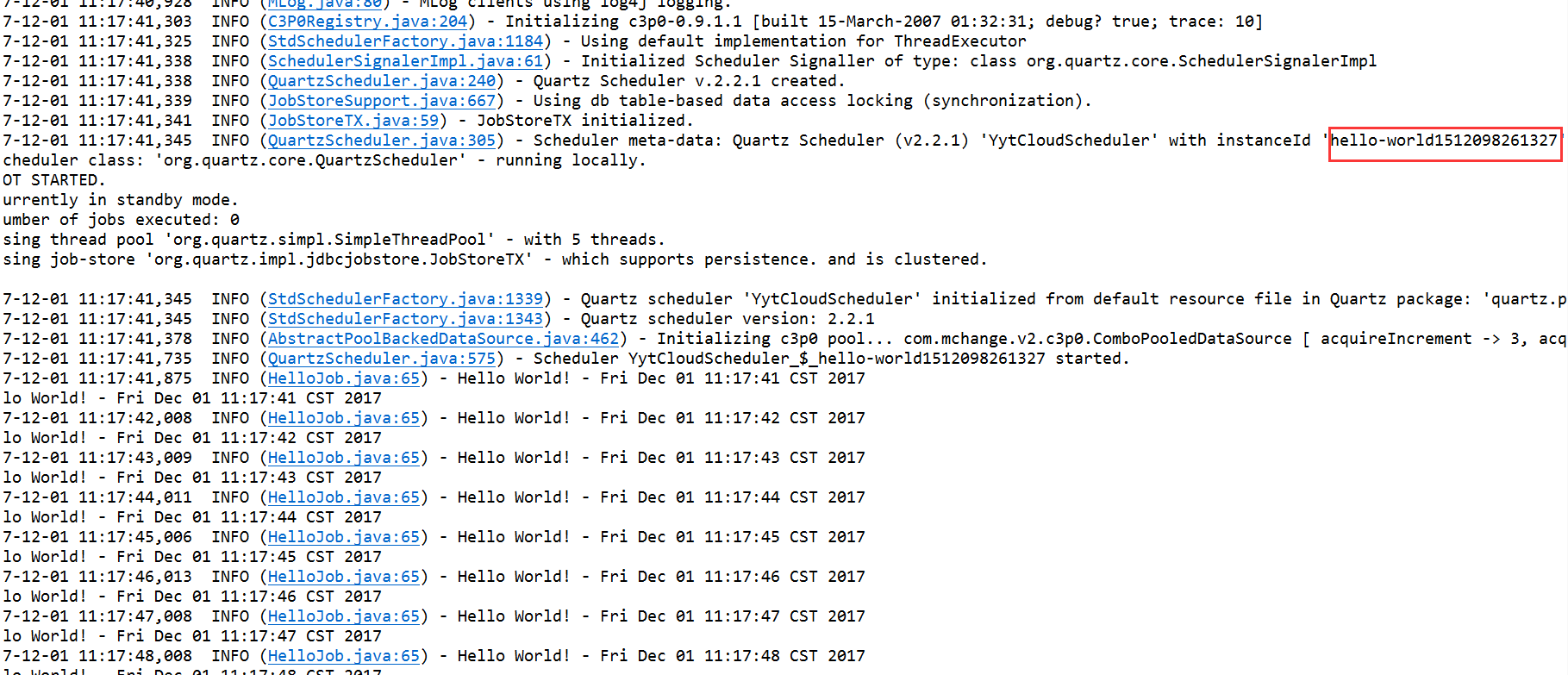
一个应用先添加任务,每秒触发任务。

集群自动分配实例ID,避免冲突,如看打印日志。
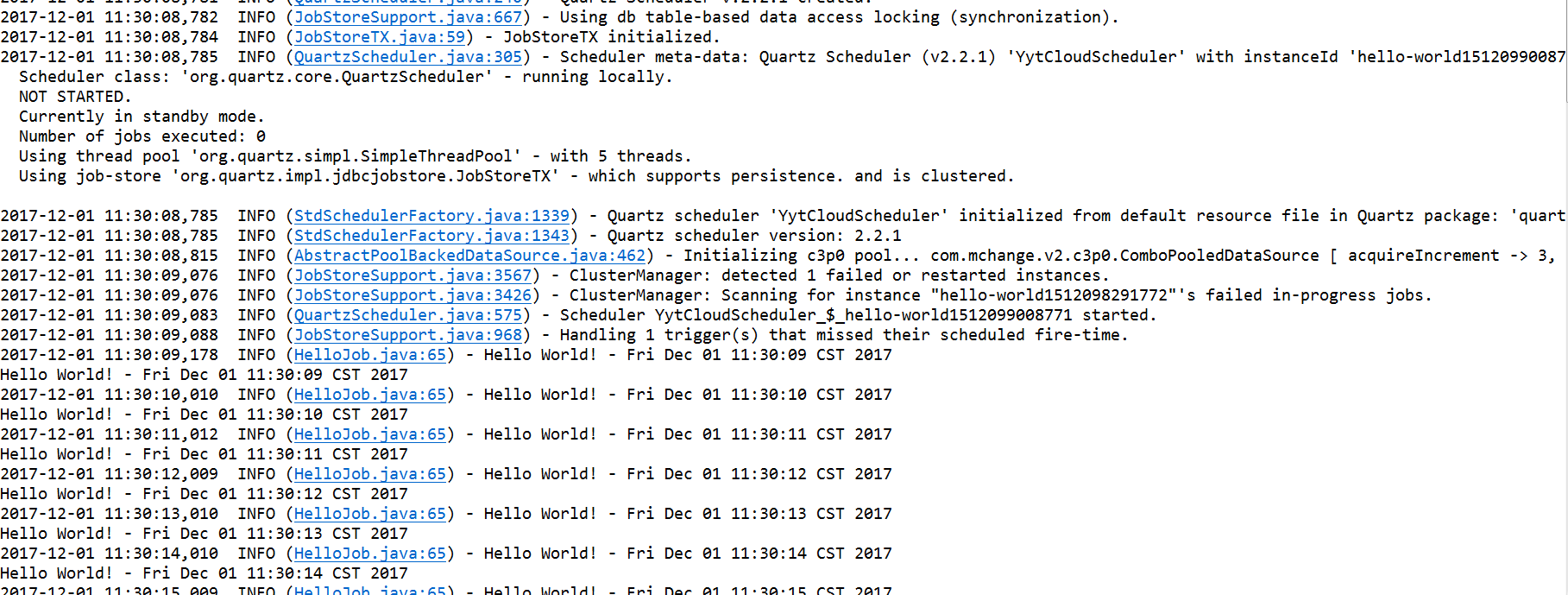
另外一个环境执行相同添加任务,则提示已经存在无法添加任务。

查看数据库,此时,任务信息持久化在表中

应用再次运行时会自动触发库中持久化的任务信息。模拟启动。
![]()
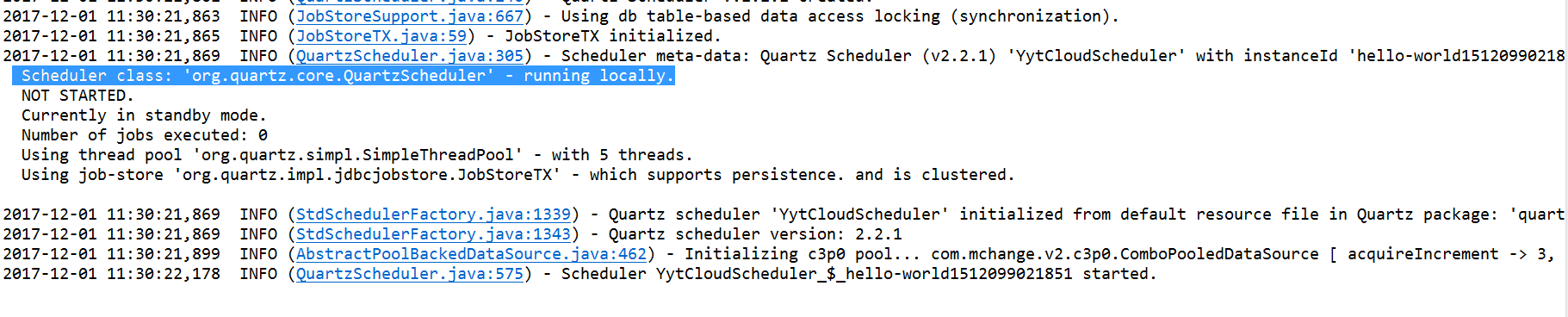
一个环境先启动,已经触发了任务。
另一个实例,没有触发任务就结束了。
验证了任务集群下是可以避免任务重复执行的。
总结
Quartz虽然强大,任务调度极其方便,易用,集群下也可以避免任务重复执行。但还是有些不足之处:节点任务调度会跟系统当前时间做比较,集群各个节点的系统时间尽可能一致,Quartz集群还发生争用数据库的情况,存在数据库单点故障,任务处理也存在应用集群下单机处理极限问题。Quartz原生也没有支持可视化监控的任务管理端。有不少分布式调度开源框架都是基于Quartz做了扩展。
参考
Quartz应用与集群原理分析 https://tech.meituan.com/mt-crm-quartz.html
基于 Quartz 开发企业级任务调度应用 https://www.ibm.com/developerworks/cn/opensource/os-cn-quartz/


One thought on “Quartz管中窥豹之集群管理”